Salts and UUIDs for your Databases – Intro

221012
This is the introductory post about Salts and UUIDs for other posts of mine on how you can implement and use them in your preferred database: MongoDB, MySQL/MariaDB, PostgreSQL, Oracle, and MS SQL Server.
Intro to UUIDs
IDs (identifiers) in database tables is the standard way to distinguish each particular record (row or entry) from the others in a table. A common way is to use your Database’s capabilities to define such a sequential integer ID, for example, by using an autoincrement counter or a pre-defined sequence that triggers for every inserted record.
However, this practice does not work well for every case, since it fails to keep your records constantly unique over different database operations, replications, transfers, etc.
Another approach widely adopted, is to use UUIDs instead, because they offer a real-world certainty for the uniqueness of our records. Generally, a Universally Unique IDentifier (UUID) is a combination of server time, clock sequence, MAC address of the main network etc. That means that UUIDs are really random generated and practically unique across all systems, unique throughout the world!
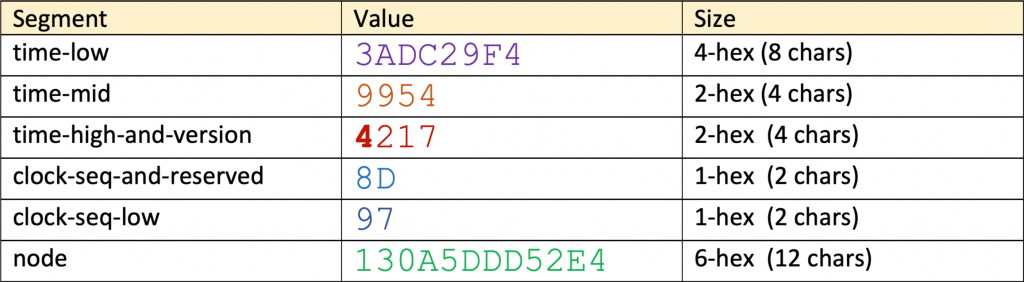
In short, a universally unique identifier (UUID) is a standardized (RFC 4122, ISO/IEC 9834-8:2005) 128-bit number represented by a utf8 string of five hexadecimal numbers in ‘aaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee’ (8-4-4-4-12) format:
- The First 8 hex digits represent an integer giving the low 32 bits of the time
- The next 4 digits represent an integer giving the middle 16 bits of the time
- The next 2 digits represent a 4-bit “version” in the most significant bits, followed by the high 12 bits of the time
- The next 2 digits represent a 1 to 3-bit “variant” in the most significant bits, followed by the 13 to 15-bit clock sequence
- The final 12 digits represent a 48-bit node (MAC address for FreeBSD/Linux or randomly generated number)
For instance:

I’m not going to waste your time, going into detail about UUIDs their evolution, and different versions. You can find dozens of information on the web. However, the table below shows what version each of the presented here databases is using by default:

Instead, what I want is to provide a grasp on you can start implementing them in the major databases, by giving you practical implementation examples.
Intro to password hashing and Salts
Password hashing
You probably are aware of hashes, the one-way mathematical functions widely used in various crypto areas. In short, hash functions can be used with any piece of data, e.g. a password string, in order to create a numeric digest that identifies uniquely the data set (the password) from which it has resulted. Practically, there is no way for one to find another (different) set of data that gives the same resulting digest using the same hash function.
It is important, to be clear that we have always to use an enough secure hash function (a secure hash algorithm) to create a unique digest for a given plain-text password. The more secure is hash-function being used, the more impossible is to find the data set that created the digest (the hash value). The process of creating a hash value from a given password is known as password hashing.
Note, that different hash algorithms produce digests (= hash values) of different sizes. However, the same hash algorithm produces always the same-length hash values, regardless of the size of the size of the input data (e.g. the password length).
For instance, the widely used SHA-256 hash algorithm produces always a 32-byte (64 hex characters) hash value.
Now, it can be understood that, instead of storing the plain passwords provided by users in a database table column, we can store hash values instead.
One can only verify if a given hash value corresponds to a given password. This can easily be done by using again the same algorithm to produce a new hash value, and then by comparing the newly created hash value with the stored hash value.
Salts
However, any attacker can use the “right” tools (significant CPU power, phishing, specialized dictionaries, etc.) and try to guess the password and/or decipher the password’s hash value. In order to make things more difficult for any ambitious attacker, we can use a technique known as ‘salting’, i.e. the process of creating a ‘salt‘ for the password hash value. Generally, a ‘salt’ is nothing but a randomly created value (e.g. a string of bytes) that is added to the password in order to compute the hash value. So, the hash value is calculated from both the salt and the password.
Since the process of verification requires the full data set (password and salt) we have somehow to make the salt also available for the verification. A widely used approach is to also add the randomly created salt to the stored hash value. The length of the salt, as well as the way a salt can be added to a hash value (e.g. to the beginning, in the end, split half and a half or differently, etc.), is up to your own logic. However, this logic should be also reflected in the verification function.
For instance, an approach could be to use as salt a randomly created value of 8-bytes (16hex characters) and put it to the beginning of the hash value, so for an SHA-256 produced hash value, the output length becomes in total 40-bytes or 80 hex characters.

Again, searching the web, you will find thousands of posts and tons of much more exhaustive information about password hashes and salts, and all related information. So, it doesn’t make any sense to go into more detail here. The recap I made above is enough for the goals of this post.
Remarks before proceeding to the posts of practical implementations
One can use either the backend/middleware to deal with UUIDs and password hashing and salts. Almost all languages and frameworks offer us the necessary functionality to use them. However, putting this logic into the backend/middleware adds some boilerplate code that should be implemented for each language or framework you use. Moreover, exposes to that layer some of the sensitive logic being used, a fact that is not always the best choice. So, a better approach is to assign to the database layer this task. This is doable because almost all databases support UUIDs and/or stored procedures/functions and triggers that do the job.
For our demo cases we will use a very simple table “demousers”, consisting of just 3 columns/fields:
- id,
- username
- password
The first one, the “id” column, will be used for UUID.
The “password” column is the one that we will use for storing passwords.
The way we will use to store our UUIDs in the id column is to use a 36-characters (32 hex characters plus the 4 dashes).
Regarding the password column, initially, when we demonstrate UUIDs, we will use it to store plain-text passwords. Then we will use it to store salted hash values of 80 hex characters.
I know that using character/text (e.g. CHAR or VARCHAR ) types for id and password columns, should not be the case for real production systems. This is because it results in more space, low indexing performance, as well as other issues (e.g. character set issues, etc.). For production systems, a better approach might prefer to use 16-byte / 40-byte type respectively. However, here we will remain “stuck” using character types, which I prefer for the demo purposes of this post.
For each one of the database cases, we will have to create and work in a database or schema (where this is available) named “ticket-management”. Inside the “ticket-management” database/schema we will create the table “demousers” and we will assign the necessary permissions/privileges to a user.
Different databases use different approaches to generate and use UUIDs and/or hashes. For instance, one can use a built-in uuid type, a built-in or imported function directly associated with the id field, using a trigger, or a combination of a stored function and a trigger, etc. So, here, we will use any of the available options that are the most suitable.
So, let’s start! Below are the posts that provide real implementation examples for each one of the major databases:





That’s it for now! I hope you enjoyed it!
Thanks for reading ? and stay tuned!